

数据孤岛源于系统异构。智造供应链的各个环节存在众多的信息系统,如MES、SRM、WMS等,不同厂家开发系统数据格式、数据存储、通信协议不一致,导致不同系统间的数据无法打通,形成数据孤岛;同时也存在企业内部各部门为了满足自身需求,对于各自收集的数据自建数据库,没有统一的数据库管理和共享机制,如销售关注客户订单数据,生产关注生产进度数据与产品质量数据,生产制造过程的仓储、运输、生产等环节的数据在不同系统形成数据割裂,产生孤岛。例如某汽车零部件工厂集成后的WMS系统仍需将数据手工导入ERP,效率提升率不超过20%。智能制造要求将不同环节、不同阶段、不同系统之间的数据打通,但由于智能制造的平台,不同厂商的设备PLC、SCADA接口不兼容等原因导致设备互联的困难,不同系统的集成费用可高达项目投资总额30%~40%。部分企业由于系统集成的失败,不得不放弃智能化改造。
很多企业导入AI赋能智造供应链系统,但是,一直以来,人们以为AI赋能智造供应链就是RPA采集数据、数据ETL、应用数理统计/ML/DL预测后续走势,然后根据走势决策,这本质上是相关性分析(以历史推断未来)而已。由于对AI的认知不够,AI与数字化之间的交互处理不合理,导致“用AI的方式,补数字化的课”。一方面,AI模型需要大量高质量的数据进行训练才能准确预测。但在制造供应链中,数据可能存在不完整、不准确、不一致等问题,影响AI模型的预测性能。另一方面,制造供应链的业务场景多样,不同环节对AI的需求和应用方式不同,需要构建可以表征因果路径的机理模型,从而推动AI决策,而不仅仅是相关性分析。例如,在需求预测中,影响参数需要考虑市场趋势、季节因素等;在库存管理中,要结合生产计划、采购周期等。这就要求AI技术能够针对不同场景进行定制化开发,增加了AI赋能的复杂性。另外,AI技术与智造供应链中的其他技术,如物联网、大数据等需要深度融合才能发挥更大作用。但这些技术在发展阶段、技术标准等方面存在差异,融合过程中会遇到技术兼容性、数据交互等问题。
在实践中,支撑AI的四大要素是:数据、算力、模型和算法。数据来源与逻辑梳理主要基于统计学习、机器学习(ML/DL)、机理建模(系统动力学)三个层级多维度展开,在数据梳理的时候,强调“数据不足模型补,模型不精大数据补”,模型和大数据双驱动。如图1所示。
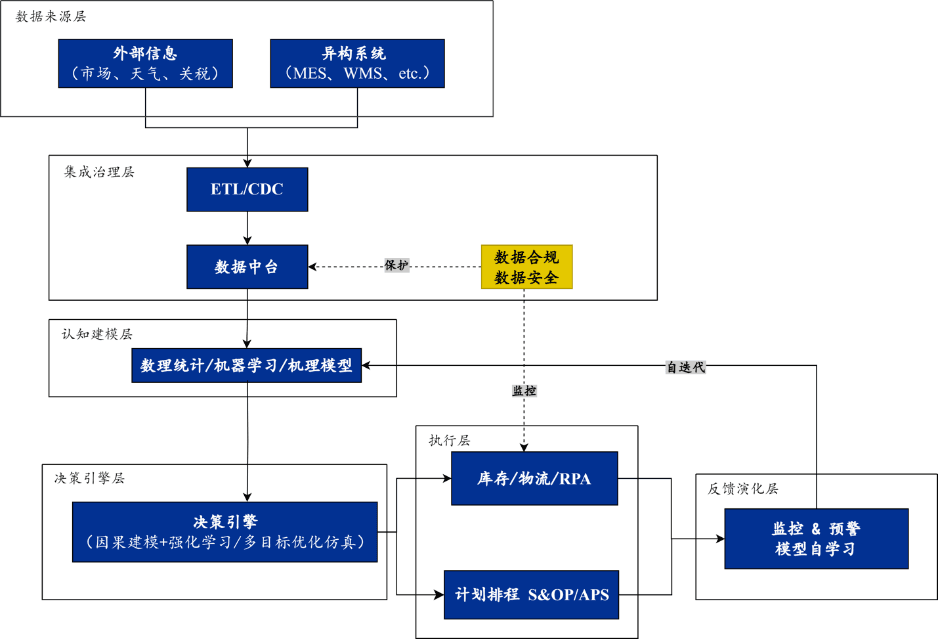
图1 AI智能赋能智造供应链逻辑
模型(比如BASS扩散模型)的稳定性不仅依赖方程本身的适定性,更需与供应链实时数据、运营规则深度耦合。而且,AI赋能的智造供应链模型需具备“动态进化”能力——数据不足时,用供应链经验规则补足;数据冗余时,用机器学习“降噪”提炼。所有参数的模型理论上都可以参数自学习(动态验证和自我进化),但是在一个从历史数据中训练得到的固定模型中,再怎么进化也跑不出模型的机理限制、数据限制。所以,企业供应链计划应机理建模为先,然后机器学习,最后统计方法补充,这是AI赋能智造供应链和其他领域的本质区别。传统供应链优化通常是机器学习和统计方法优先,没有足够的懂供应链原理的专家知识来机理建模。
所以,AI赋能的智造供应链会从解决问题转向定义问题。在这个新阶段,Evaluation(模型评估) 会比 Training (模型训练)更重要,这对人们“学习能力”提出挑战。
除了系统集成的“结构性风险”之外,系统集成后会有诸如数据泄露、网络攻击等更大程度上的安全风险。由于系统本身复杂性增加,一旦某一个环节发生故障,将可能波及整个供应链系统,这对供应链的可靠性保证提出了更高的要求,故系统集成的难度以及复杂程度会加大。